Quick and accurate data capture is essential in fast-moving and dynamic industrial workflows. One important requirement in data capture applications is capturing text from surfaces and products, even in extreme circumstances like uneven color. While it is possible to train deep learning models for capturing text (OCR), due to the nature of deep learning models, it requires a lot of contextual data to train them from scratch.
Let’s take the example of Black on Black text which we can find in vehicle tires, like the one below.

Traditional OCR solutions fail miserably in capturing this kind of data. Training models from scratch to extract this kind of data requires a huge amount of data. Then, there are practical concerns about the data distribution of characters in the data we collect. It will be hard to collect data in a manner where each alphabet is equally distributed across the dataset. Every deep-learning engineer hates the imbalanced class problem.
And, as a deep learning engineer, if you are presented with a new complicated OCR problem, you’ll want to take advantage of unrelated larger datasets for OCR and then use them for your use case.
You would have already encountered the term transfer learning. We believe transfer learning is one of the most underrated and most important techniques in deep learning.

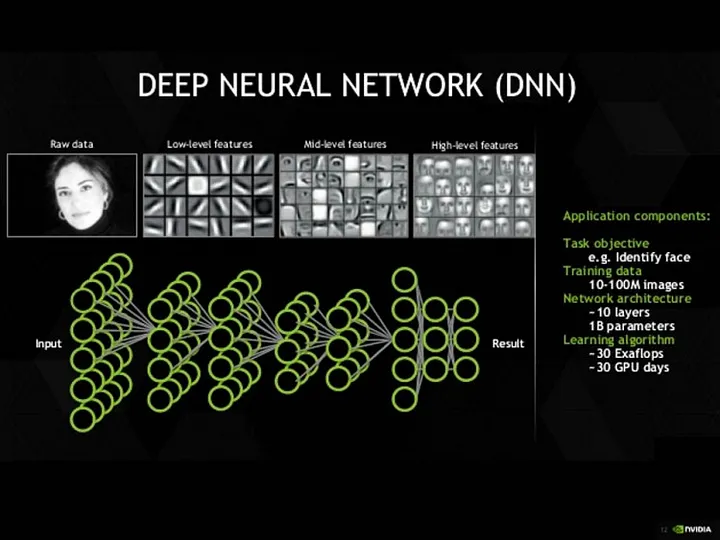
The core idea about transfer learning is that models have multiple layers, each layer is responsible for identifying features. The latter layers in the model build on top of the features learnt in the earlier layers. In the case of Convolutional Neural Networks, the earlier layers learning primitive features like dashes, lines and as we move to consecutive layers, the learned primitive features are then combined to detect much more complicated features.
Let’s look at an example for the above example:
The low-level features and sometimes even the mid-level level features needn’t be specific to a single task at hand but could be used across different tasks. For example, the features that define a human’s face could also be generalized across other animal species. The features of a cricket bat could be quite similar to a baseball bat. It is only in the high-level features that are learned in the latter part of the neural network would we see highly specialized task specific features.
Use of transfer learning in computer vision took off back in 2016, but its use in NLP is fairly recent with the explosion of Large Language Models (LLMs).
The idea behind transfer learning is that you train a model on a large dataset, and then use the same model which has learned the features from the large dataset, to train on smaller task-specific data. The core reason behind this is that most of the features learned for the large dataset are common across many other image recognition tasks.
This removes the need to collect huge amounts of task-specific data and reduces training time.
This has given rise to an entire research field that is known as few-shot learning.
One-shot learning is a very popular strategy used in facial recognition and signature-matching technologies.
The way one-shot learning works is by training a model that learns to predict the difference aka similarity score between two given inputs, be it text or images. These kinds of models don’t learn to classify images, but rather learn the features alone and then predict how different the two images are.
This way, for example in the case of facial recognition, you don’t have to train a classifier for the model to recognize each person in your organization. All you have to do is train a model on a set of paired images of people and then have the model learn their similarities or dissimilarity.
Then, all you need is a couple of images from every employee or member in your organization and that’ll be enough to identify to make predictions, irrespective of whether the model has seen images of the person.
This is why it is called one-shot learning. It is because the model doesn’t need any idea about the new people or faces that it has to classify. All you need is one sample image of the person’s face and one new real-time image from a security camera to classify that the face from the image of the camera is the same as the one from the sample image.
Few-shot learning is about using transfer learning, but only training the model for a few epochs using less amount of data, maybe around 5 or so.
Personally, we believe that few-shot learning is among the most under-explored and underappreciated techniques in Deep Learning.
Now, how can this be used in OCR?
You can take large-scale synthetic text datasets like the Synth90K dataset and then train your recognition models on the same, which could be a CRNN model or a character recognition pipeline. This allows the pipeline to learn features specific to words and characters from the target language.
Once you train them on these synthetic datasets, you can then take the same pipeline and train them on smaller datasets that are task-specific, like the picture at the top of this post, black-on-black embedded text, which might not be properly recognized by generalized OCR solutions.